Building the First Historical Dictionary of Bengali
Following up on the success of the Tagore Online Variorum Bichitra, the School of Cultural Texts and Records at Jadavpur University has embarked on a still more ambitious project: to create a historical dictionary of the Bengali language, to which we have given the name Shabdakalpa. A historical dictionary analyses a comprehensive database of words in a language to find when each word was first used, and all subsequent changes in form, meaning and usage. It is the most basic tool for studying all uses and applications of the language.
Such dictionaries exist only in certain Western languages, often as works in progress. A start was made with Bengali by the Dhaka Bangla Academy. With the greatest respect for this pioneering effort, we can claim in all modesty that our project marks a quantum expansion of scale. The methodology of such projects has been revolutionized with the coming of the computer; but the final analysis of data can only be done by the human intelligence. On the one hand, the project thus involves a complex and advanced computer program; on the other, highly skilled and labour-intensive human analysis.
The computational processing comprises three chief tasks. First, to compile the largest possible database of Bengali texts of all periods on all subjects. We have downloaded a huge number of Bengali texts from the internet. We are now completing that task and adding much material from other online and offline sources. Some libraries and archives have kindly made their collections available, and of course we have our own collections too.
A considerable amount of labour is involved in assembling the texts, documenting their metadata, and converting them into a format suitable for use with our software. Although many of these texts are available online in the form of PDF files, they are not immediately usable in their existing format. Therefore, each file must undergo conversion into plain text (.txt) format using Optical Character Recognition (OCR) technology, which allows us to extract machine-readable content from scanned or image-based documents. This step is essential for enabling further analysis and digital processing.
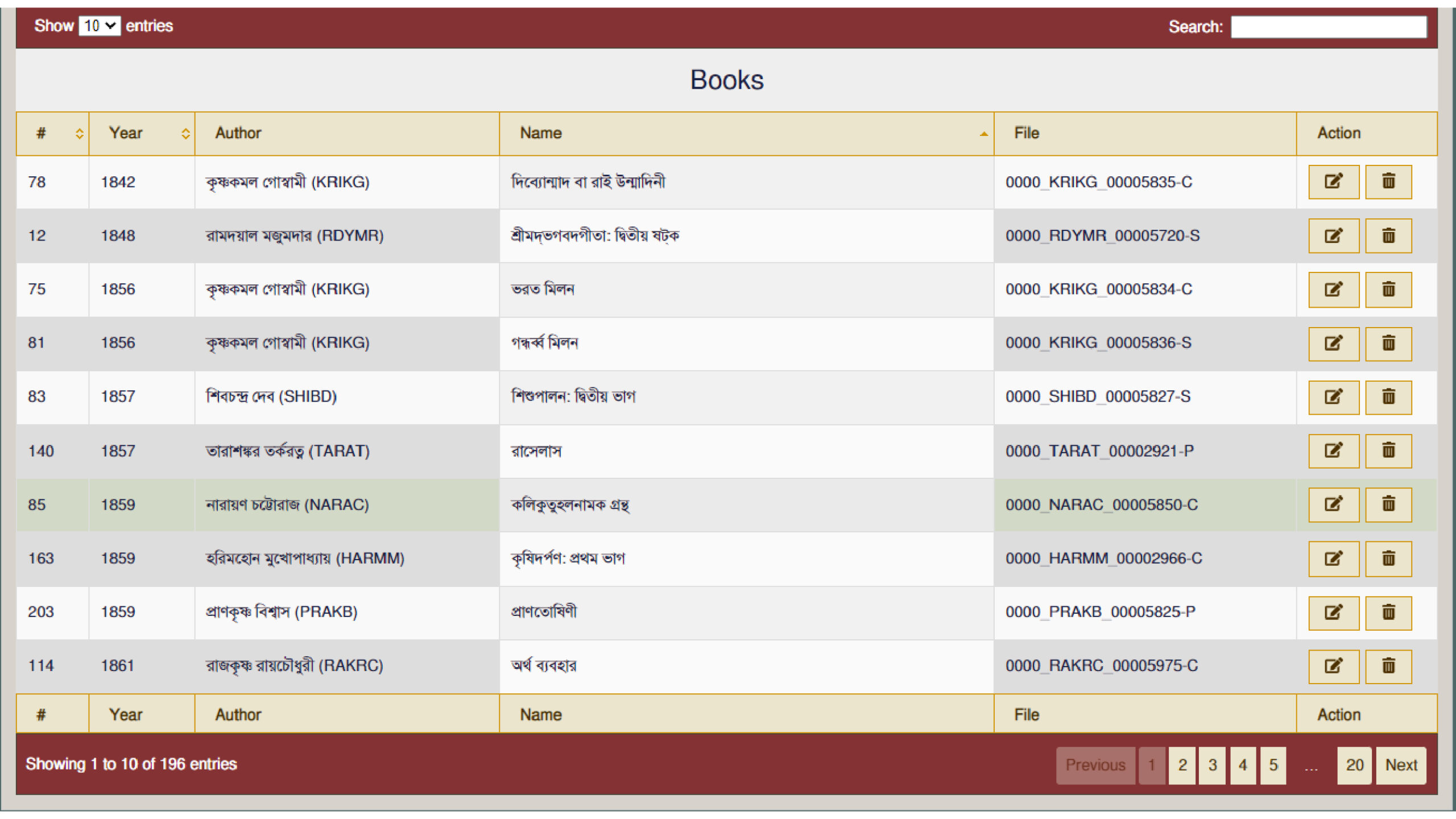
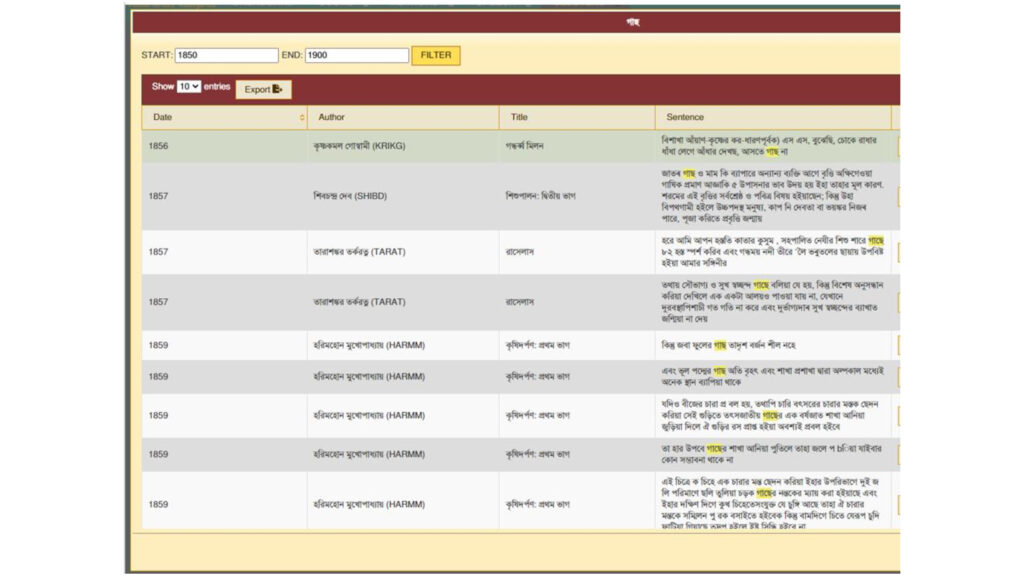
Here is a page of our working software. It lists the works by author, title and date. Clicking on the appropriate link opens a full word list.
[The display is modified from time to time. The current display may not match what you see, but the process remains the same.]
Creating this database is a vast and potentially never-ending task. Our aim is to reach a certain critical mass, from which to develop a prototype dictionary. This will meet most needs of most people, and can serve in future as the basis for a truly comprehensive dictionary, growing dynamically like the language itself.
The second, even more challenging task is to create a software to process the raw data of the texts. This software is complete: the biggest milestone we have achieved so far. There was nothing like it before. Having got so far, we feel more than ever that we must put the software to use by actually completing the dictionary.
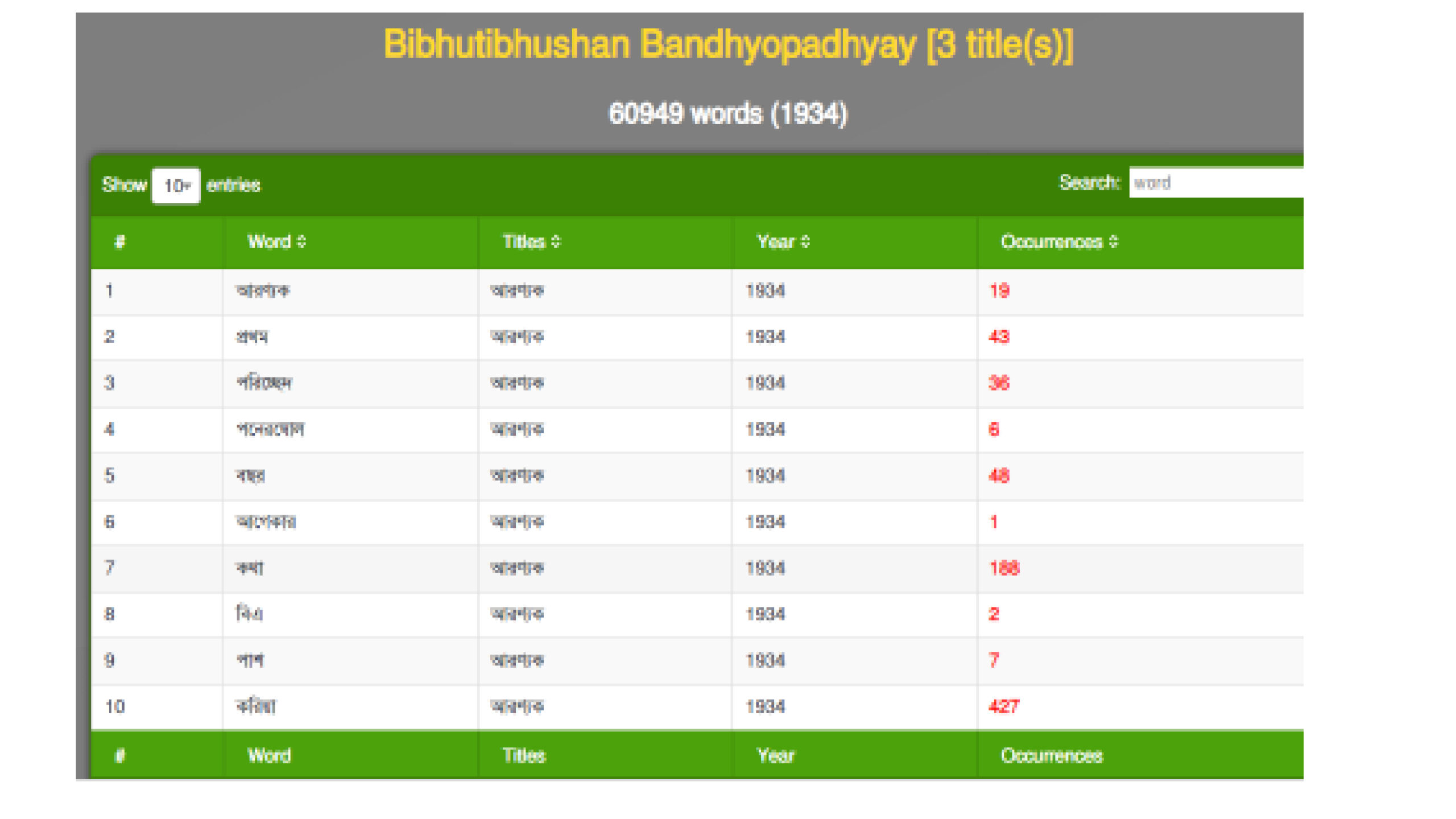
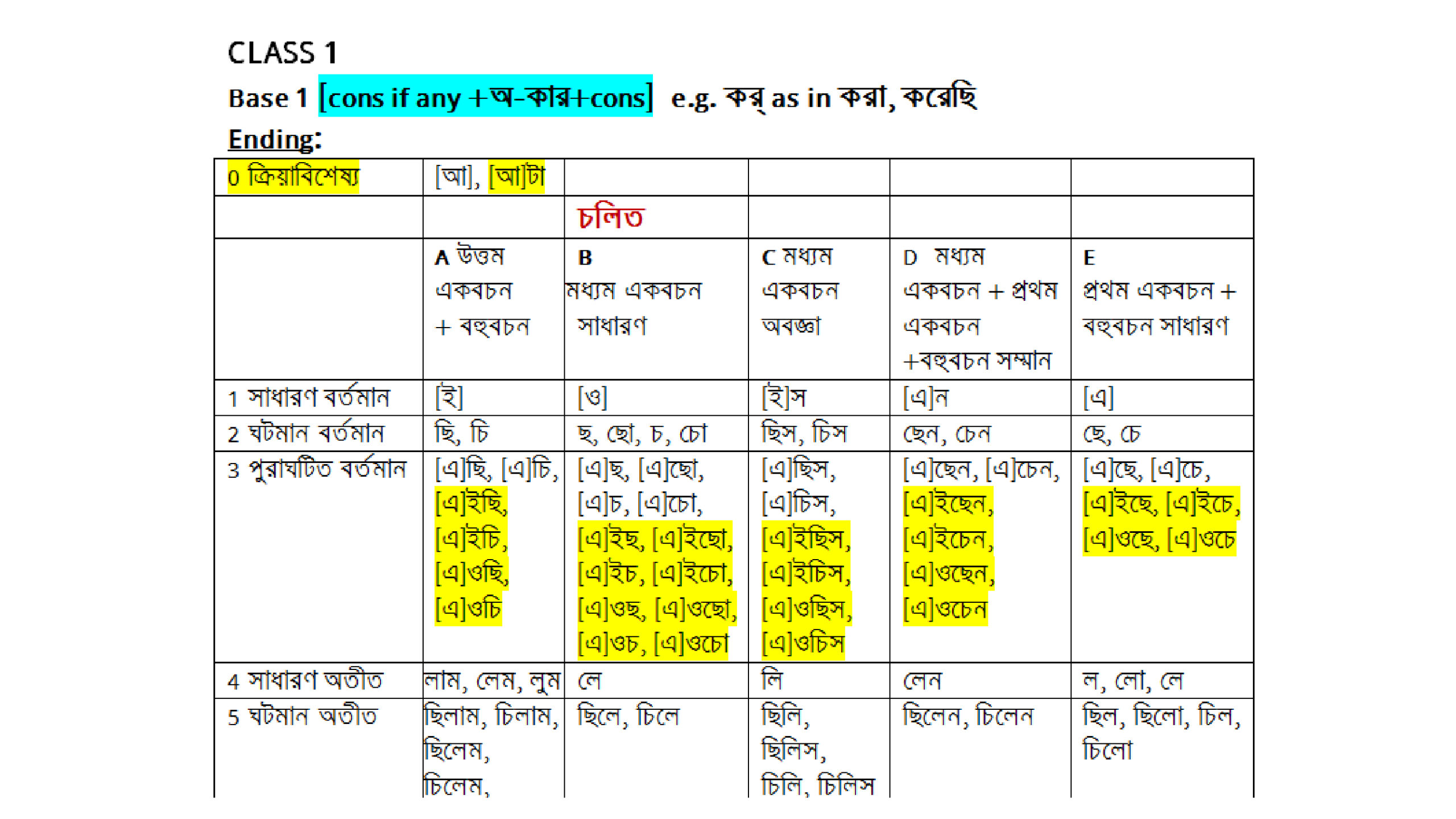
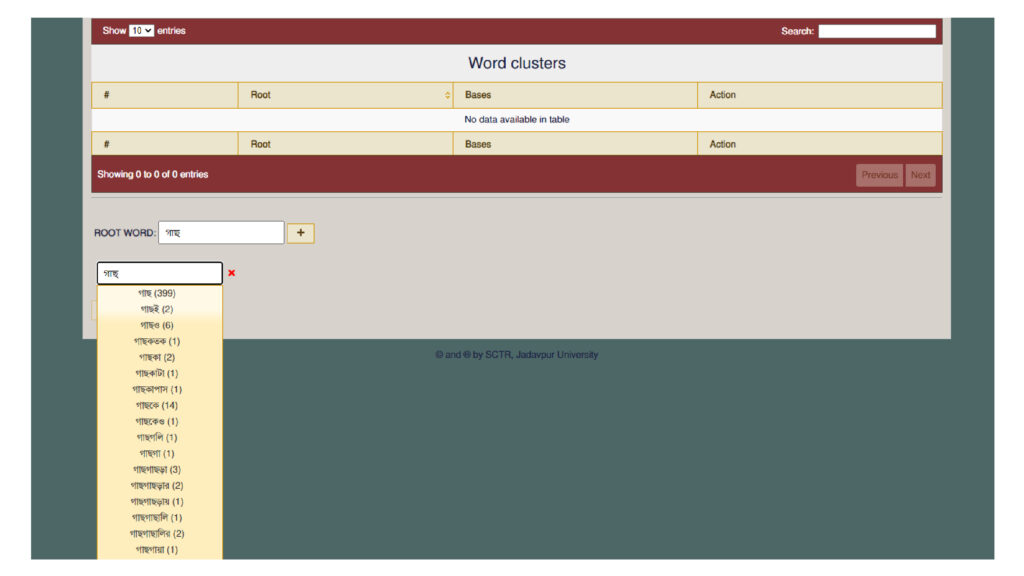
Extracting a list of words from the database is simple enough. The challenge is to group together all forms of the same word to create the total picture. Bangla is a highly inflected language, more so in having two separate registers, sadhu and chalit. A Bengali verb can have 100-150 different forms, or even more. Nouns take on a variety of suffixes – গাছ, গাছটা, গাছের, গাছগুলো, etc. etc. These too must be aggregated.
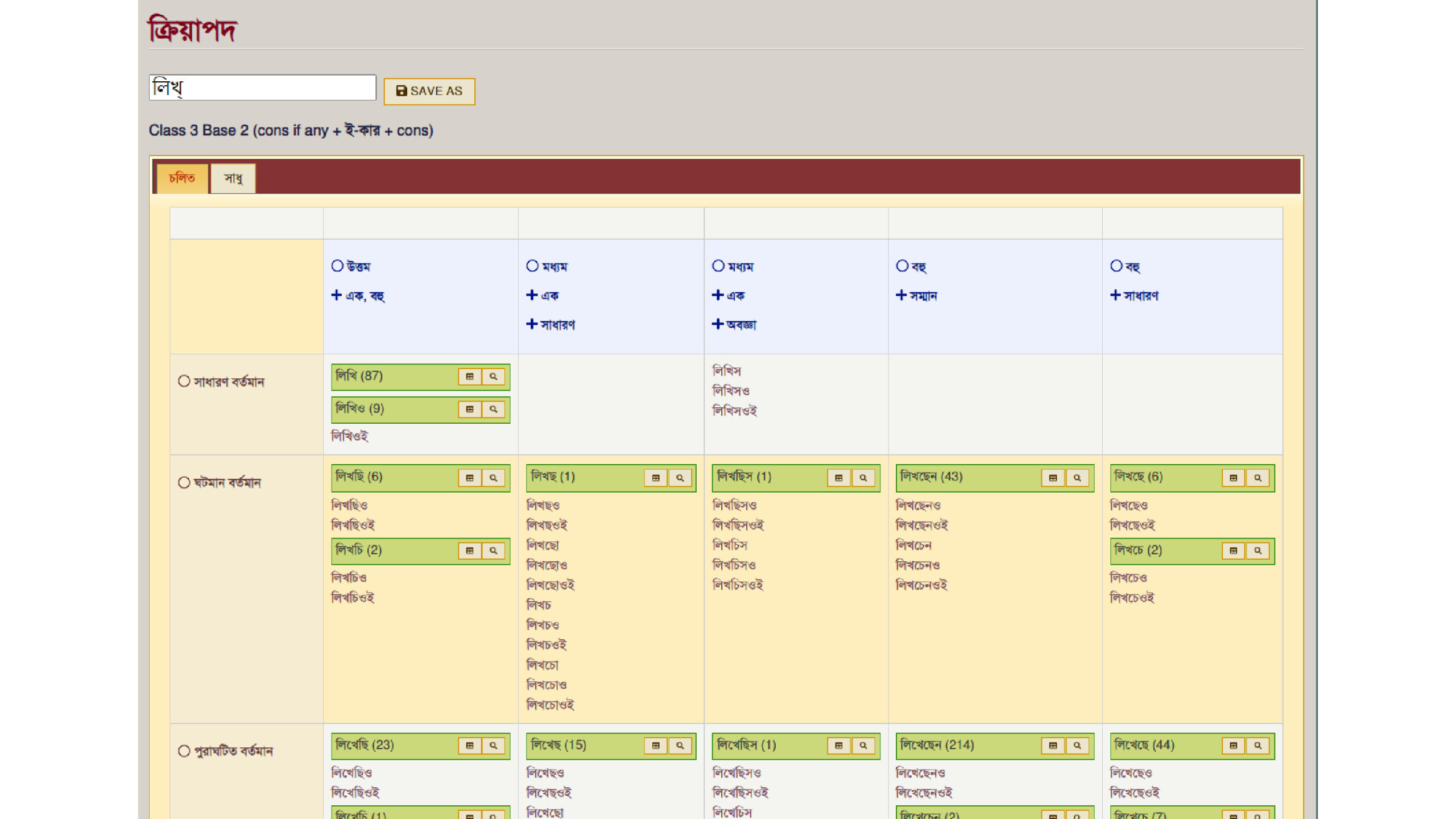
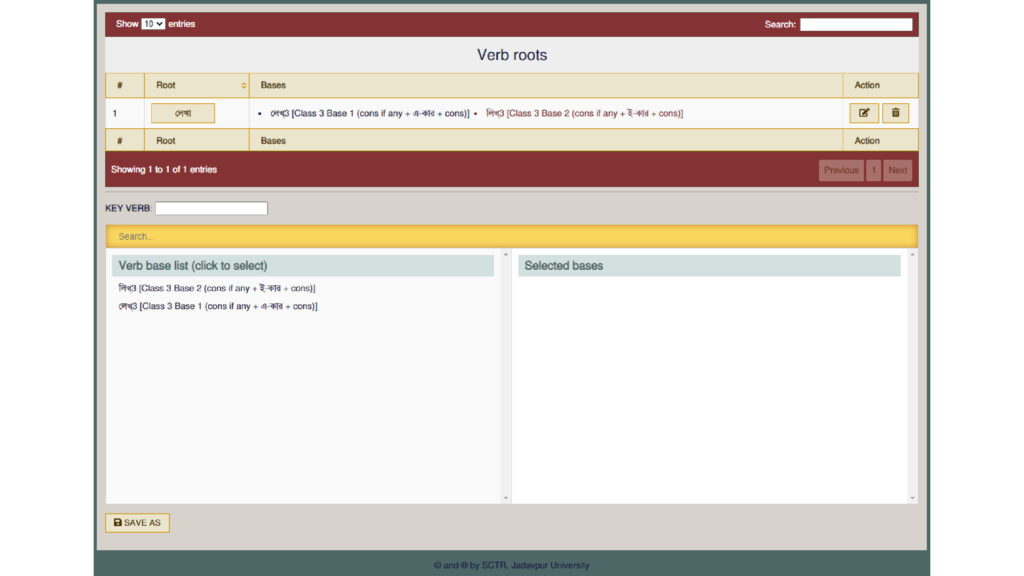
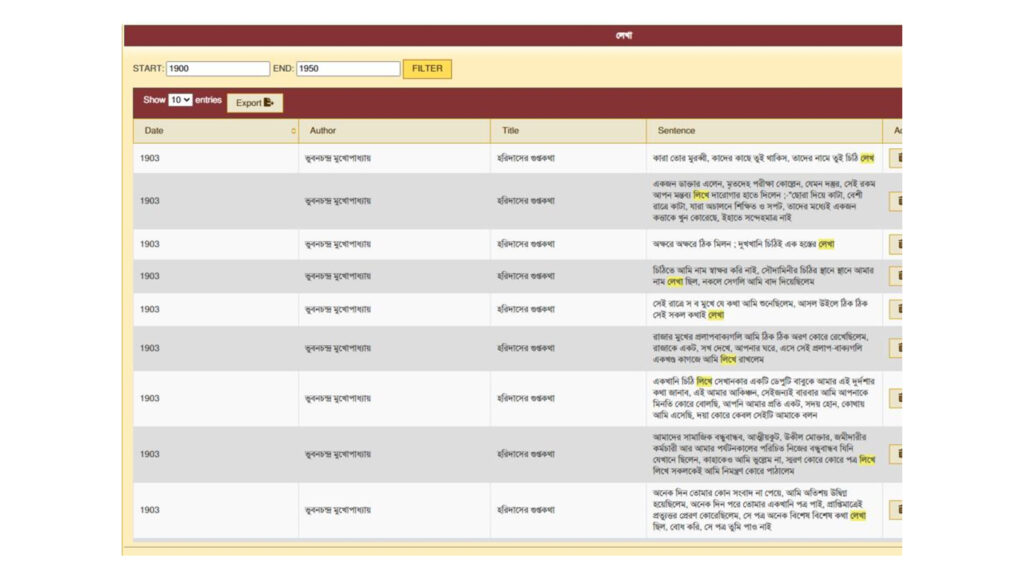
Our path-breaking software can create a table of all forms of a verb with the same base, and record every example of every form found in the database. Here, for instance, is a table outlining all forms of the verb লেখা with the base লেখ্: সে লেখে , তুমি লেখো , তুই লেখ etc. Click on any of the forms, and you will get a complete list of all its examples, with author, source and date.
Here is a similar table for the other base of the verb, লিখ্ – আমি লিখি , তুমি লিখবে, তিনি লিখিতেছিলেন etc.
The next step is to ‘club’ or combine the two tables to produce the final list, of all occurrences of all forms of the verb in both লেখ্ and লিখ্, arranged in order of date with author and source
By a different but similar process, all forms of a noun – say, গাছ – can be aggregated into a single list of all forms. And so with pronouns, or any other part of speech.
Once the computer has done its job, the results can be transferred to a spreadsheet. Now comes the third and last stage: the human brain analyses the results, sorts the examples by meaning and usage, and reorganizes the data into the final dictionary entry. Even here, computer programs can play a supporting role. We already have one such program, a part of speech tagger that lets us separate different parts of speech with the same external form, like the verb কর (=করো ), ‘do’, and the noun কর (hand, or tax).
Shabdakalpa: A Legacy in the Making
What use will Shabdakalpa serve? Why should we want to complete it? It is the most fundamental resource for every kind of use to which we might put the language. Looked at another way, it is like an encyclopedia of exceptionally fine granularity for all aspects of Bengal and Bengali. A language endowed with a historical dictionary has made it to a very special league among the world’s languages. As the world’s seventh most widely spoken language, Bengali amply deserves this recognition.
We have come a good distance in creating this proud cultural asset for our language. But a long road remains ahead. Please help us to complete the journey.